一文带你快速入门Go语言
万丈高楼平地起,勿以浮沙筑高台。
学习一门语言或者新技术、新知识,就像盖房子,必须要打好基础。盖房子如果基础打的不好,房子盖的越高越难盖,房子的寿命也不会长,早晚会塌。就像武侠小说里面的绝世武功,练习者必须要先习得内功心法,再去研习一些精妙的招数,这样武功才会达到上乘境界。学习一门语言也是一样,我们必须要脚踏实地,从最基础的语言结构、语法学起,切忌急于求成。这里我们只讲go语言该如何入门,当然其他的计算机语言也是一样的道理。如果在学习go语言之前,你已经掌握了一两门语言,并且对C语言的基础语法和语言结构有了解,那么学习起来会相对轻松一些。
hello world:
package main
import "fmt"
func main() {
fmt.Println("Hello, World!")
}字符串string
一个字符串是一个不可改变的字节序列。文本字符串通常被解释为采用UTF8编码的Unicode码点(rune)序列。
内置的len函数
len函数可以返回一个字符串中的字节数目(不是rune字符数目),索引操作s[i]返回第i个字节的字节值
s := "hello, world"
fmt.Println(len(s)) // "12"
fmt.Println(s[0], s[7]) // "104 119" ('h' and 'w')
ss := "你好,世界"
fmt.Println(len(ss)) // "15" 每个汉字占三个字节子字符串操作
fmt.Println(s[0:5]) // "hello"对所有的字符串操作超出len(s)范围,会报panic异常
子字符串链接
fmt.Println(s[0:5] + " world") // "hello world"字符串转义
双引号包含的字符串,可以用以反斜杠\开头的转义序列插入任意的数据。下面的换行、回 车和制表符等是常见的ASCII控制代码的转义方式:
\a 响铃
\b 退格
\f 换页
\n 换行
\r 回车
\t 制表符
\v 垂直制表符
\' 单引号 (只用在 '\'' 形式的rune符号面值中)
\" 双引号 (只用在 "..." 形式的字符串面值中)
\\ 反斜杠反引号的用法
反引号 ` 包含的字符串中没有转义操作,全部都是字面意思。通常用于正则表达式和定义一个多行字符串。
s := `你好,世界
这里是go语言
`
fmt.Println(s) // “这里是go语言”会换行显示字符串修改
字符串是不可变的,尝试直接修改字符串内部数据会报panic异常,需要先将字符串转换为[]byte类型
func changeString() {
s1 := "big"
// 强制类型转换
byteS1 := []byte(s1)
byteS1[0] = 'p'
fmt.Println(string(byteS1))
s2 := "白萝卜"
runeS2 := []rune(s2)
runeS2[0] = '红'
fmt.Println(string(runeS2))
}字符串编码
Go语言的源文件采用UTF8编码,并且Go语言处理UTF8编码的文本也很出色。unicode包提供了诸多处理rune字符相关功能的函数(比如区分字母和数组,或者是字母的大写和小写转换等),unicode/utf8包则提供了用于rune字符序列的UTF8编码和解码的功能。
计算字符串中字符的个数
s := "hello,世界"
fmt.Println(utf8.RuneCountInString(s)) // 8字符串和数字转换
- 字符串转整数 如果要将一个字符串解析为整数,可以使用strconv包的Atoi或ParseInt函数 ParseInt函数的第三个参数是用于指定整型数的大小;例如16表示int16,0则表示int。在任何情况下返回的结果y总是int64类型,你可以通过强制类型转换将它转为更小的整数类型。
x, err := strconv.Atoi("123") // x is an int
y, err := strconv.ParseInt("123", 10, 64) // base 10, up to 64 bits- 数字转字符串
x := 123.33
y := fmt.Sprintf("%v", x)
fmt.Printf("%T\n", y) //string
fmt.Printf("%T\n", x) //float64
fmt.Println(y) // 123.33比较重要的几个标准库
标准库中有四个包对字符串处理尤为重要:bytes、strings、strconv和unicode包。
字符串操作例子
- 字符串包含子串
func Contains(s, substr string) bool {
for i := 0; i < len(s); i++ {
if HasPrefix(s[i:], substr) {
return true
}
}
return false
}- 字符串前缀和后缀
func HasPrefix(s, prefix string) bool {
return len(s) >= len(prefix) && s[:len(prefix)] == prefix
}
func HasSuffix(s, suffix string) bool {
return len(s) >= len(suffix) && s[len(s)-len(suffix):] == suffix
}- 文件名称去除后缀
func basename(s string) string {
// Discard last '/' and everything before.
for i := len(s) - 1; i >= 0; i-- {
if s[i] == '/' {
s = s[i+1:]
break
}
}
// Preserve everything before last '.'.
for i := len(s) - 1; i >= 0; i-- {
if s[i] == '.' {
s = s[:i]
break
}
}
return s
}或
func basename(s string) string {
slash := strings.LastIndex(s, "/") // -1 if "/" not found
s = s[slash+1:]
if dot := strings.LastIndex(s, "."); dot >= 0 {
s = s[:dot]
}
return s
}- 实现每隔三个字符插入一个逗号
func comma(s string) string {
n := len(s)
if n <= 3 {
return s
}
return comma(s[:n-3]) + "," + s[n-3:]
}数值类型
整型
整型分为以下两个大类: 按长度分为:int8、int16、int32、int64 对应的无符号整型:uint8、uint16、uint32、uint64 其中,uint8就是我们熟知的byte型
- 十进制整数打印
var a int = 10
fmt.Printf("%d \n", a)浮点型
Go语言支持两种浮点型数:float32和float64。这两种浮点型数据格式遵循IEEE 754标准: float32 的浮点数的最大范围约为 3.4e38,可以使用常量定义:math.MaxFloat32。 float64 的浮点数的最大范围约为 1.8e308,可以使用一个常量定义:math.MaxFloat64。
通常应该优先使用float64类型,因为float32类型的累计计算误差很容易扩散,并且float32能精确表示的正整数并不是很大
- 浮点数打印
fmt.Printf("%f\n", math.Pi)复数
complex64和complex128
var c1 complex64
c1 = 1 + 2i
var c2 complex128
c2 = 2 + 3i
fmt.Println(c1)
fmt.Println(c2)复数有实部和虚部,complex64的实部和虚部为32位,complex128的实部和虚部为64位。
数值运算
算术和逻辑运算的二元操作中必须是相同的类型。 浮点数到整数的转换将丢失任何小数部分。
- 计算浮点数和整数的和
a := 1
b := 1.3
v := float64(a) + b // 必须先转换
fmt.Println(v) // 2.3常量
常量表达式的值在编译期计算,而不是在运行期。每种常量的潜在类型都是基础类型:boolean、string或数字。(常量范围目前只支持布尔型,数字型(整型,浮点型,复数)和字符串型)
- 常量的定义
常量定义上可以分为显式和隐式: 显式:
const identifier [type] = value隐式:
const identifier = value // 通常叫无类型常量组合的方式定义:
const(
cat string = "猫"
dog = "狗"
go = false
)常量可以使用内置表达式定义,例如:len(),unsafe.Sizeof()等
- 特殊常量:iota
iota在const关键字出现时被重置为0 const体中每新增一行常量声明将使iota计数一次(即加1)
const (
n1 = iota //0
n2 //1
n3 //2
n4 //3
)iota常见使用方法: 跳值使用法
const (
n1 = iota //0
n2 //1
_
n4 //3
)插队使用法
const (
n1 = iota //0
n2 = 100 //100
n3 = iota //2
n4 //3
)
const n5 = iota //0单行使用法
const n = iota //0表达式隐式使用法
const (
a, b = iota + 1, iota + 2 //1,2
c, d //2,3
e, f //3,4
)数组
数组是一个由固定长度的特定类型元素组成的序列,一个数组可以由零个或多个元素组成。 因为数组的长度是固定的,因此在Go语言中很少直接使用数组。通常会使用对应的类型slice(切片)
数组的每个元素可以通过索引下标来访问,索引下标的范围是从0开始到数组长度减1的位置。内置的len函数将返回数组中元素的个数。
初始化
默认情况下,数组的每个元素都被初始化为元素类型对应的零值,对于数字类型来说就是0。我们也可以 使用数组字面值语法用一组值来初始化数组:
var q [3]int = [3]int{1, 2, 3}
var r [3]int = [3]int{1, 2}
fmt.Println(r[2]) // "0"数组的长度是数组类型的一个组成部分,因此[3]int和[4]int是两种不同的数组类型。数组的长度必须是常量表达式,因为数组的长度需要在编译阶段确定。
省略号...
如果在数组的长度位置出现的是“...”省略号,则表示数组的长度是根据初始化值的个数来计算:
q := [...]int{1, 2, 3}
fmt.Printf("%T\n", q) // "[3]int"指定下标初始化
定义一个含有100个元素的数组r,最后一个元素被初始化为-1,其它元素都是用0初始化
r := [...]int{99: -1}数组的比较
如果一个数组的元素类型是可以相互比较的,那么数组类型也是可以相互比较的,这时候我们可以直接 通过==比较运算符来比较两个数组,只有当两个数组的所有元素都是相等的时候数组才是相等的
a := [2]int{1, 2}
b := [...]int{1, 2}
c := [2]int{1, 3}
fmt.Println(a == b, a == c, b == c) // "true false false"
d := [3]int{1, 2}
fmt.Println(a == d) // compile error: cannot compare [2]int == [3]int函数中的使用
我们可以显式地传入一个数组指针,那样的话函数通过指针对数组的任何修改都可以直接反馈到 调用者。
func zero(ptr *[32]byte) {
for i := range ptr {
ptr[i] = 0
}
}或者
func zero(ptr *[32]byte) {
*ptr = [32]byte{}
}切片
Slice(切片)代表变长的序列,序列中每个元素都有相同的类型。一个slice类型一般写作[]T,其中T代表slice中元素的类型;slice的语法和数组很像,只是没有固定长度而已,slice在底层引用了一个数组对象。
长度和容量
slice的长度对应slice中元素的数目; 长度不能超过容量,容量一般是从slice的开始位置到底层数据的结尾位置。内置的len和cap函数分别返回slice的长度和容量。
slice的切片操作s[i:j],其中0 ≤ i≤ j≤ cap(s),用于创建一个新的slice,引用s的从第i个元素开始到第j-1个元素的子序列。
切片操作超出cap(s)的上限将导致一个panic异常,但是超出len(s)则是意味着扩展了slice
我们先定义一个底层数组:
months := [...]string{1: "January", /* ... */, 12: "December"}让我们分别定义表示第二季度和北方夏天月份的slice,它们有重叠部分: 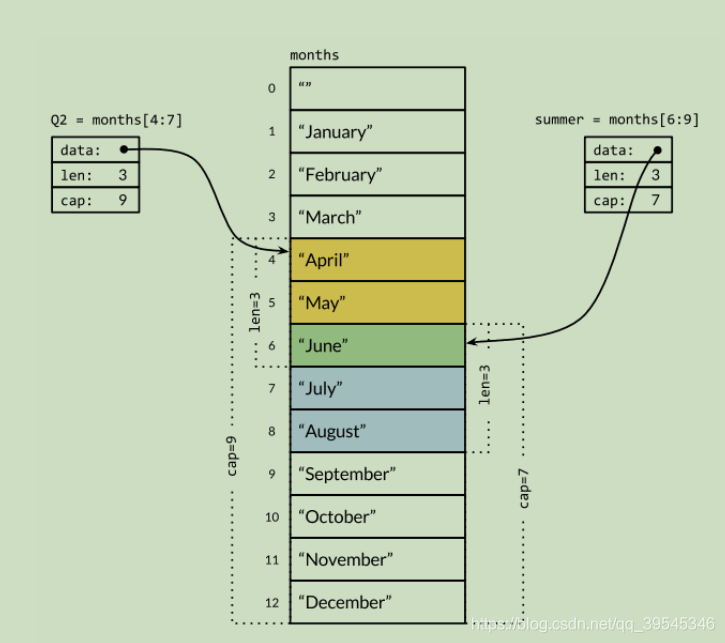
Q2 := months[4:7]
summer := months[6:9]
fmt.Println(Q2) // ["April" "May" "June"]
fmt.Println(summer) // ["June" "July" "August"]我们可以看到,切片操作s[i:j]返回新的slice,它的长度len是j-i,它的容量cap是底层数组的长度减去开始截取的元素所在的索引 i
slice的比较
两个slice之间不能做比较,slice唯一合法的操作是和nil做比较,例如:
if summer == nil { /* ... */ }slice计算长度
如果你需要测试一个slice是否是空的,使用len(s) ==0 来判断,而不是 s == nil来判断。
slice赋值拷贝
下面的例子,展示了slice底层公用一个数组
func main() {
s1 := make([]int, 3) //[0 0 0]
s2 := s1 //将s1直接赋值给s2,s1和s2共用一个底层数组
s2[0] = 100
fmt.Println(s1) //[100 0 0]
fmt.Println(s2) //[100 0 0]
}append函数
Go语言的内建函数append()可以为切片动态添加元素。 可以一次添加一个元素,可以添加多个元素,也可以添加另一个切片中的元素(后面加…)。
func main(){
var s []int
s = append(s, 1) // [1]
s = append(s, 2, 3, 4) // [1 2 3 4]
s2 := []int{5, 6, 7}
s = append(s, s2...) // [1 2 3 4 5 6 7]
}一次性追加多个元素
var citySlice []string
// 追加一个元素
citySlice = append(citySlice, "北京")
// 追加多个元素
citySlice = append(citySlice, "上海", "广州", "深圳")
// 追加切片
a := []string{"成都", "重庆"}
citySlice = append(citySlice, a...)
fmt.Println(citySlice) //[北京 上海 广州 深圳 成都 重庆]copy函数的使用
Go语言内建的copy()函数可以迅速地将一个切片的数据复制到另外一个切片空间中,copy()函数的使用格式如下:
copy(destSlice, srcSlice []T)其中: srcSlice: 数据来源切片 destSlice: 目标切片
示例:
func main() {
// copy()复制切片
a := []int{1, 2, 3, 4, 5}
c := make([]int, 5, 5)
copy(c, a) //使用copy()函数将切片a中的元素复制到切片c
fmt.Println(a) //[1 2 3 4 5]
fmt.Println(c) //[1 2 3 4 5]
c[0] = 1000
fmt.Println(a) //[1 2 3 4 5]
fmt.Println(c) //[1000 2 3 4 5]
}切片删除元素
go语言没有提供删除元素的函数,我们根据slice本身特性来删除
func main() {
// 从切片中删除元素
a := []int{30, 31, 32, 33, 34, 35, 36, 37}
// 要删除索引为2的元素
a = append(a[:2], a[3:]...)
fmt.Println(a) //[30 31 33 34 35 36 37]
}总结:要从切片a中删除索引为index的元素,操作方法是a = append(a[:index], a[index+1:]...)
Map
map是一种无序的基于key-value的数据结构,Go语言中的map是引用类型,必须初始化才能使用。它得内部基于散列表(hash)实现
定义语法
map[KeyType]ValueTypeKeyType:表示键的类型。 ValueType:表示键对应的值的类型。
map初始化和赋值
方法一:
scoreMap := make(map[string]int, 8)
scoreMap["张三"] = 90
scoreMap["小明"] = 100
fmt.Println(scoreMap)
fmt.Println(scoreMap["小明"])
fmt.Printf("type of a:%T\n", scoreMap)方法二:
userInfo := map[string]string{
"username": "沙河小王子",
"password": "123456",
}
fmt.Println(userInfo) //判断某个键是否存在
value, ok := map[key]示例:
func main() {
scoreMap := make(map[string]int)
scoreMap["张三"] = 90
scoreMap["小明"] = 100
// 如果key存在ok为true,v为对应的值;不存在ok为false,v为值类型的零值
v, ok := scoreMap["张三"]
if ok {
fmt.Println(v)
} else {
fmt.Println("查无此人")
}
}map删除元素
delete(map, key)其中,
map:表示要删除键值对的map key:表示要删除的键值对的键
map遍历
依然和slice一样,使用for range遍历
func main() {
scoreMap := make(map[string]int)
scoreMap["张三"] = 90
scoreMap["小明"] = 100
scoreMap["王五"] = 60
for k, v := range scoreMap {
fmt.Println(k, v)
}
}指定顺序遍历
因为map是无序的,所以想要实现有序遍历,需要借助其他数据类型,比如slice
func main() {
rand.Seed(time.Now().UnixNano()) //初始化随机数种子
var scoreMap = make(map[string]int, 200)
for i := 0; i < 100; i++ {
key := fmt.Sprintf("stu%02d", i) //生成stu开头的字符串
value := rand.Intn(100) //生成0~99的随机整数
scoreMap[key] = value
}
//取出map中的所有key存入切片keys
var keys = make([]string, 0, 200)
for key := range scoreMap {
keys = append(keys, key)
}
//对切片进行排序
sort.Strings(keys)
//按照排序后的key遍历map
for _, key := range keys {
fmt.Println(key, scoreMap[key])
}
}切片与map
我们来简单介绍一下map类型中的元素是slice的情况,以及slice类型中的元素是map的情况下的使用
- 切片中的元素为map类型时的操作:
func main() {
var mapSlice = make([]map[string]string, 3)
for index, value := range mapSlice {
fmt.Printf("index:%d value:%v\n", index, value)
}
fmt.Println("after init")
// 对切片中的map元素进行初始化
mapSlice[0] = make(map[string]string, 10)
mapSlice[0]["name"] = "王五"
mapSlice[0]["password"] = "123456"
mapSlice[0]["address"] = "红旗大街"
for index, value := range mapSlice {
fmt.Printf("index:%d value:%v\n", index, value)
}
}map中的元素为slice类型时的操作
func main() {
var sliceMap = make(map[string][]string, 3)
fmt.Println(sliceMap)
fmt.Println("after init")
key := "中国"
value, ok := sliceMap[key]
if !ok {
value = make([]string, 0, 2)
}
value = append(value, "北京", "上海")
sliceMap[key] = value
fmt.Println(sliceMap)
}指针
任何程序数据载入内存后,在内存都有他们的地址,这就是指针。而为了保存一个数据在内存中的地址,我们就需要指针变量。
取地址和取值
Go语言中的指针不能进行偏移和运算,因此Go语言中的指针操作非常简单,我们只需要记住两个符号:&(取地址)和*(根据地址取值)。Go语言中的值类型(int、float、bool、string、array、struct)都有对应的指针类型,如:*int、*int64、*string等。
取变量指针的语法:
ptr := &v // v的类型为T其中:
v:代表被取地址的变量,类型为T ptr:用于接收地址的变量,ptr的类型就为* T,称做T的指针类型。* 代表指针。
示例:
func main() {
a := 10
b := &a
fmt.Printf("a:%d ptr:%p\n", a, &a) // a:10 ptr:0xc00001a078
fmt.Printf("b:%p type:%T\n", b, b) // b:0xc00001a078 type:*int
fmt.Println(&b) // 0xc00000e018
}b := &a的图示: 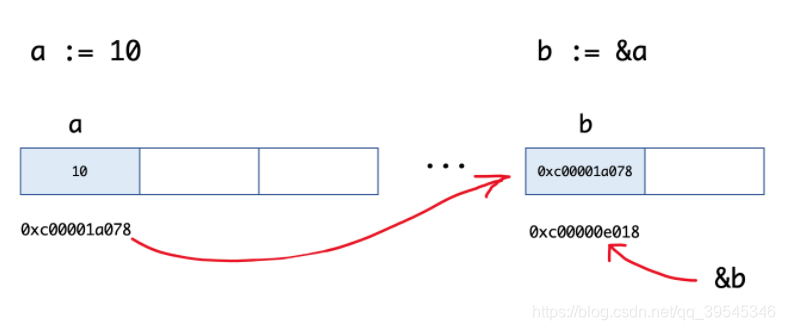 变量、指针地址、指针变量、取地址、取值的相互关系和特性如下:
变量、指针地址、指针变量、取地址、取值的相互关系和特性如下:
对变量进行取地址(&)操作,可以获得这个变量的指针变量。 指针变量的值是指针地址。 对指针变量进行取值(*)操作,可以获得指针变量指向的原变量的值。
空指针
当一个指针被定义后没有分配到任何变量时,它的值为 nil
空指针的判断:
package main
import "fmt"
func main() {
var p *string
fmt.Println(p)
fmt.Printf("p的值是%v\n", p)
if p != nil {
fmt.Println("非空")
} else {
fmt.Println("空值")
}
}new 和 make
在Go语言中对于引用类型的变量,我们在使用的时候不仅要声明它,还要为它分配内存空间,否则我们的值就没办法存储。而对于值类型的声明不需要分配内存空间,是因为它们在声明的时候已经默认分配好了内存空间。要分配内存,就引出来今天的new和make
- new 使用new函数得到的是一个类型的指针,并且该指针对应的值为该类型的零值
func main() {
a := new(int)
b := new(bool)
fmt.Printf("%T\n", a) // *int
fmt.Printf("%T\n", b) // *bool
fmt.Println(*a) // 0
fmt.Println(*b) // false
}- make make也是用于内存分配的,区别于new,它只用于slice、map以及chan的内存创建,而且它返回的类型就是这三个类型本身,而不是他们的指针类型,因为这三种类型就是引用类型,所以就没有必要返回他们的指针了
func main() {
var b map[string]int
b = make(map[string]int, 10)
b["测试"] = 100
fmt.Println(b)
}- new 和 make的区别
- 二者都是用来做内存分配的。
- make只用于slice、map以及channel的初始化,返回的还是这三个引用类型本身;
- 而new用于类型的内存分配,并且内存对应的值为类型零值,返回的是指向类型的指针。
函数
函数是组织好的、可重复使用的、用于执行指定任务的代码块
go语言中函数的特点
- 支持不定变参。
- 支持多返回值。
- 支持命名返回参数。
- 支持匿名函数和闭包。
- 函数也是一种类型,一个函数可以赋值给变量。
- 不支持嵌套 一个包不能有两个名字一样的函数。
- 不支持重载。
- 不支持默认参数。
函数定义
func 函数名(参数)(返回值){
函数体
}- 函数名:由字母、数字、下划线组成。但函数名的第一个字母不能是数字。
- 参数:参数由参数变量和参数变量的类型组成,多个参数之间使用,分隔。
- 返回值:返回值由返回值变量和其变量类型组成,也可以只写返回值的类型,多个返回值必须用()包裹,并用,分隔。
- 函数体:实现指定功能的代码块。
可变参数
可变参数是指函数的参数数量不固定。Go语言中的可变参数通过在参数名后加...来标识。 固定参数搭配可变参数使用时,可变参数要放在固定参数的后面 可变参数在函数体中的类型是一个切片
示例:
func intSum2(x ...int) int {
fmt.Println(x) //x是一个切片
sum := 0
for _, v := range x {
sum = sum + v
}
return sum
}返回值
go语言中支持函数有多个返回值
func calc(x, y int) (int, int) {
sum := x + y
sub := x - y
return sum, sub
}也支持定义时直接给返回值命名,函数中可以直接使用这些变量,最后通过return关键字返回。
func calc(x, y int) (sum, sub int) {
sum = x + y
sub = x - y
return
}变量作用域
- 全局变量:定义在函数外部的变量,它在程序整个运行周期内都有效。
- 局部变量:函数内定义的变量、语句块中定义的变量
- 函数内定义的变量无法在该函数外使用,如果局部变量和全局变量重名,优先访问局部变量。
defer
Go语言中的defer语句会将其后面跟随的语句进行延迟处理。在defer归属的函数即将返回时,将延迟处理的语句按defer定义的逆序进行执行
func main() {
fmt.Println("start")
defer fmt.Println(1)
defer fmt.Println(2)
defer fmt.Println(3)
fmt.Println("end")
}输出:
start
end
3
2
1匿名函数
匿名函数就是没有函数名的函数,匿名函数因为没有函数名,所以没办法像普通函数那样调用,所以匿名函数需要保存到某个变量或者作为立即执行函数
func main() {
// 将匿名函数保存到变量
add := func(x, y int) {
fmt.Println(x + y)
}
add(10, 20) // 通过变量调用匿名函数
//自执行函数:匿名函数定义完加()直接执行
func(x, y int) {
fmt.Println(x + y)
}(10, 20)
}闭包
包指的是一个函数和与其相关的引用环境组合而成的实体。简单来说,闭包=函数+引用环境
func adder() func(int) int {
var x int
return func(y int) int {
x += y
return x
}
}
func main() {
var f = adder()
fmt.Println(f(10)) //10
fmt.Println(f(20)) //30
fmt.Println(f(30)) //60
f1 := adder()
fmt.Println(f1(40)) //40
fmt.Println(f1(50)) //90
}函数作为参数或返回值
函数作为参数:
func add(x, y int) int {
return x + y
}
func calc(x, y int, op func(int, int) int) int {
return op(x, y)
}
func main() {
ret2 := calc(10, 20, add)
fmt.Println(ret2) //30
}函数作为返回值
func do(s string) (func(int, int) int, error) {
switch s {
case "+":
return add, nil
case "-":
return sub, nil
default:
err := errors.New("无法识别的操作符")
return nil, err
}
}panic/recover
panic可以在任何地方引发一个错误,终止程序。recover只有在defer调用的函数中有效
- recover()必须搭配defer使用。
- defer一定要在可能引发panic的语句之前定义。
func funcA() {
fmt.Println("func A")
}
func funcB() {
defer func() {
err := recover()
//如果程序出出现了panic错误,可以通过recover恢复过来
if err != nil {
fmt.Println("recover in B")
}
}()
panic("panic in B")
}
func funcC() {
fmt.Println("func C")
}
func main() {
funcA()
funcB()
funcC()
}小技巧
- 下载Go模块太慢?可以使用https://goproxy.cn/